
From REINFORCE to GRPO
This blog is an aggregate of various papers, blogs, and videos I have been going through over the last few weeks. The goal is to give a step-by-step mathematical explanation of how Large Language Models (LLMs) learn to reason using Reinforcement Learning (RL). We will start from the fundamentals, move through the REINFORCE algorithm, then Actor-Critic methods, Trust Region Policy Optimization (TRPO), Proximal Policy Optimization (PPO), and eventually arrive at Group Relative Policy Optimization (GRPO) and some of its variants such as Dr. GRPO. Rather than explaining each method independently, I will try to show how they are connected, why each method was introduced, and how one naturally leads to the next.
Introduction
I don't think reinforcement learning needs a long explanation, to be honest. A simple classical example is usually enough.
Say you have a dog and you want to teach it something, like fetching a ball. You throw the ball, and the dog runs after it, picks it up, and brings it back to you. If the dog does this correctly, you give it a treat (a reward). If it does something else, you don't give it a treat (no reward). Over time, the dog learns that fetching the ball leads to a reward, so it starts doing that behavior more often.
This is essentially what we do in reinforcement learning. We have an agent (the dog) that interacts with an environment (the world) and learns to take actions (fetching the ball) that maximize some notion of cumulative reward (treats).
Formalizing the Objective
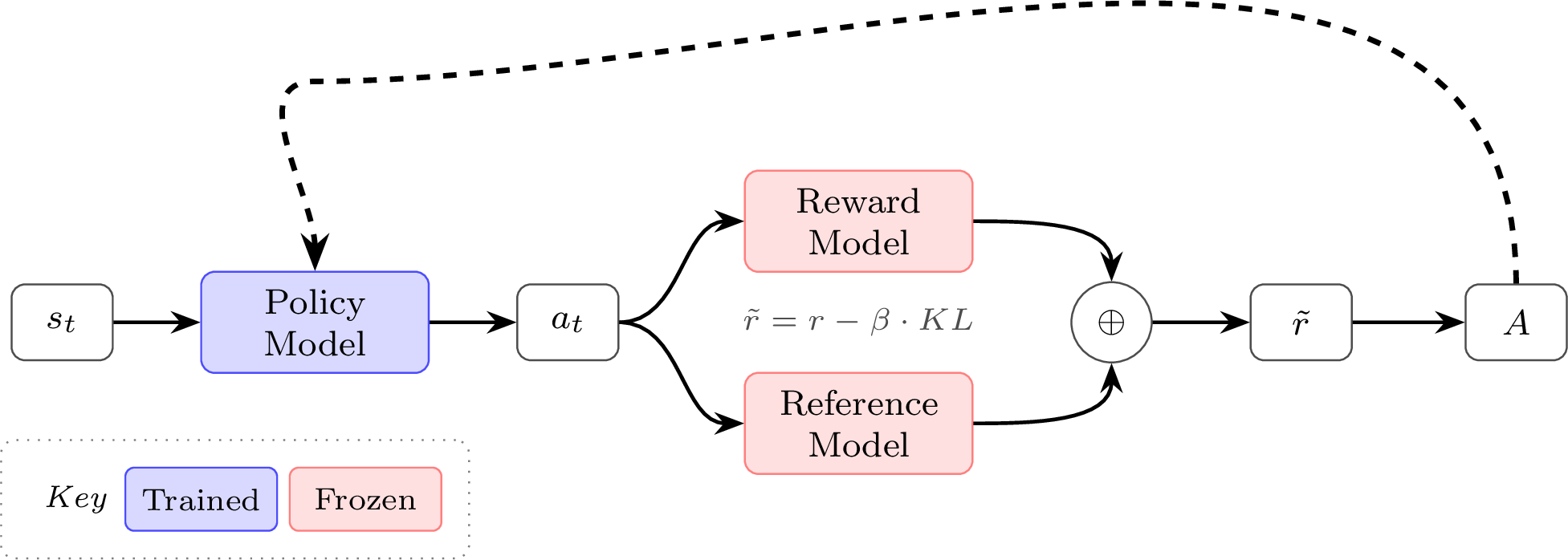
Let the initial prompt be state . The language model acts as our policy, denoted by , parameterized by . It takes the current state (the prompt + previous tokens) and outputs a probability distribution over the next token . A full sequence of states and actions is called a path, or a trajectory, denoted by :
The environment provides a reward at each time step, denoted by . There is also a discount factor , which controls how much we value future rewards relative to immediate ones. When , all rewards are weighted equally (undiscounted); when , future rewards are exponentially down-weighted. The total discounted reward for a trajectory is:
Goal: We want to find the parameters that maximize the expected reward over all possible trajectories:
I would also like to point out three quantities that we will see throughout this blog:
- Value function: : expected future return starting from state .
- Action-value function: : expected future return starting from state and taking action .
- Advantage function: : how much better is action than the average action at state . If it's positive, then reinforce; if it's negative, then suppress; and if it's zero, then do nothing.
REINFORCE
The REINFORCE algorithm, introduced by Williams in 1992, estimates policy gradients using Monte-Carlo sampled trajectories to optimize the policy parameters .
REINFORCE belongs to the broader family of Vanilla Policy Gradient (VPG) methods. VPG refers to the basic policy gradient approach where the policy parameters are updated directly using gradient ascent on expected return, without additional stabilization techniques such as clipping, trust regions, or actor-critic bootstrapping.
We begin with the objective:
This expectation can be written as a sum over all trajectories:
where the probability of a trajectory is
Here:
- is the initial state distribution
- is the policy
- represents environment dynamics
Taking the gradient with respect to :
Expanding the trajectory probability:
Taking the logarithm:
Now differentiate with respect to :
- The environment dynamics do not depend on
- The initial state distribution also does not depend on
Therefore,
Substituting this back into the objective gradient gives
This is the REINFORCE gradient estimator, which forms the basis of Vanilla Policy Gradient methods.
However, using the full trajectory return for every action can lead to very high variance. Every action is weighted using the final outcome of the entire episode, even though many rewards may not actually be caused by that specific action.
Instead, we use the future return starting from timestep :
The gradient now becomes
This works because an action at timestep cannot influence rewards that occurred before timestep .
Even with future returns, the gradient estimate can still have high variance. To reduce this variance, we subtract a baseline that does not depend on the sampled action:
Therefore, the objective can be rewritten as
When the baseline is chosen as the value function , the quantity
is called the advantage. It measures whether an action performed better or worse than the policy's average expectation for that state.
Why use a baseline?
Without a baseline, every action is weighted directly by the raw return . But this only tells us whether the episode outcome was good or bad overall — not whether the action itself was better or worse than expected.
This creates high variance because the return mixes together:
- The quality of the action
- The quality of the state the agent was already in
As a result, a good action taken in a bad state and a bad action taken in a good state can produce similar returns.
Subtracting a baseline centers the learning signal:
Instead of asking:
"Was the return high?"
the policy gradient now asks:
"Was this action better or worse than expected in this state?"
Commonly used baselines include:
- Moving average reward
- Batch mean reward (used carefully in practice)
- Learned value function
References
- Nathan Lambert, Louis Castricato, Leandro von Werra, and Alex Havrilla. "Reinforcement Learning from Human Feedback: From Zero to Hero." rlhfbook.com, 2024.
Discussion
Add a Comment
Markdown Guide
*text***text**[text](url)`code`__text__> text~~text~~Comments