Introduction to DRL
What is deep reinforcement learning?
Deep reinforcement learning(DRL) is a machine learning approach to articial intelligence concerned with creating computer programs that can solve problems requiring intelligence. The distinct property of DRL programs is learning through trial and error from feedback that’s simultaneously sequential, evaluative, and sampled by leveraging powerful non-linear function approximation.
Deep reinforcement learning is a machine learning approach to AI. All computer programs that display intelligence can be considered as AI but not every AI can learn. ML is the area of AI whihc create computer programs that can solve problems requiring intelligence by learning from data. There are 3 main branches of ML:
- Supervised learning
- Unsupervised learning
- reinforcement learning
Main branches of machine learning.
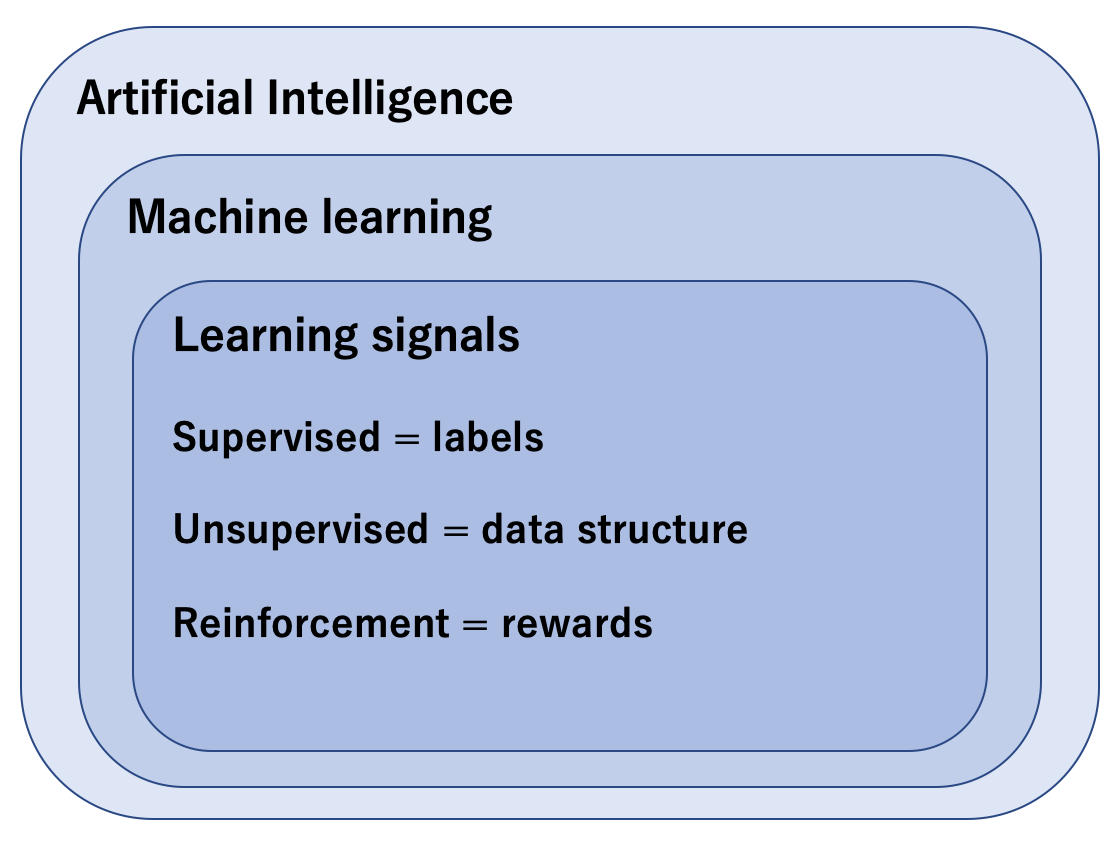
Supervised learning (SL): is the task of learning from labeled data. In SL, ahuman decides which data to collect and how to label it. The goal in SL is to generalize. eg. Image classification.
Unsupervised Learning (UL): is the task of learning from unlabeled data. Even though data no longer needs labeling, the methods used by the computer to gather still need to be designed by a human. eg. A customer segmentation application.
Reinforcement learning: is the task of learning through trial and error. The goal of RL is to act. eg. Ping-Pong playing agent.
Deep learning(DL) which is not a seperate branch of ML is a collection of techniques and methods for using neural networks to solve ML tasks, whether SL, UL or RL. DRL is simply the use of DL to solve RL tasks. ie. DRL is an approach to a problem.
In DRL an agent is decision maker. On the other side of the agent is the environment. The environment is everything outside the agent; everything that the agent has no control over. The strict boundary between the agent and the environment is counterintutive at first but the decision maker, the agent, can only have a single role and that is to make decisions. Everything else is bundled with environment.
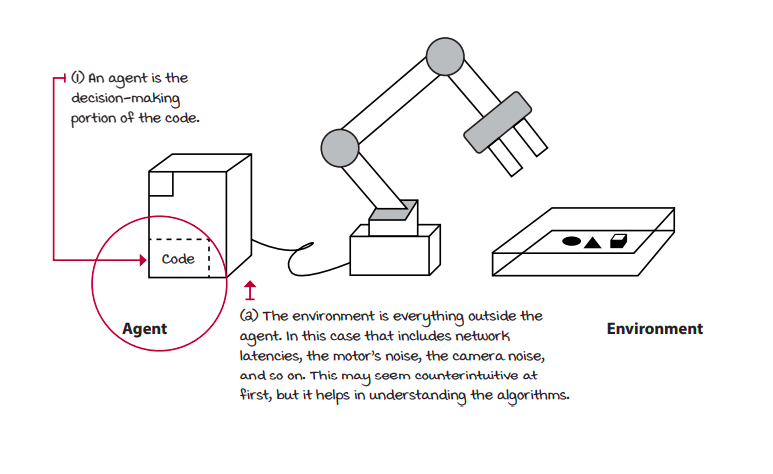
The environment is represented by a set of variables related to the problem. eg. The location, velocity of a robotic arm would be a part of variables that make up the environment. This set of variables and all possible values that they can take are referred to state space. A state is an instantiation of the state space, a set of values the variables take.
Some time agents don’t have access to the actual full state of environment. The part of a state that are observed by agents is called observation.
State vs Observation: Given an image with some shapes in it. State iff. we are given with all data’s(position). But it is just an observation if we aren provided with incomplete information and sometimes can be noisy.
At each state, the environment makes available a set of actions the agent can choose from. The agent influences the environment through these actions. The environment may change states as a response to the agents’s action. The function that’s responsible for this mapping is called the transition function. The environment may also provide a reward signal as a response. The function responsible for this mapping is called the reward function. The set of transition and reward functions is referred to as the model of the environment.
The cycle
- The cycle begins with agent observing the environment.
- The agent uses this observation and reward to attempt to improve at the task.
- It the sends an action to the environment in an attempt to control it in a favorable way.
- Finally the environment transitions and its internal state changes as a consequence of the previous state and the agent’s action. Then the cycle repeats.
The environment commonly has a well defined task. The goal of this task is defined through reward function. Reward function signals can be sequential, evaluative and sampled.
The agent has a three-step process: Agent interact with the environment, the agent evaluates its behavior, and the agent improves its response. The agent can be designed to learn mappings from observation to actions called Policies. The agents can be designed to learn the model of the environment on mapppings called models. The agents can be designed to learn to estimate the reward-to-go on mapping called value functions.
The interactions between agents and environment may go for several cycles and each of these cycles are called a time step. At each time step, agent observes environment, takes action, recieve a new observation and reward. The set of state, action, reward, and the new state is called an experience.
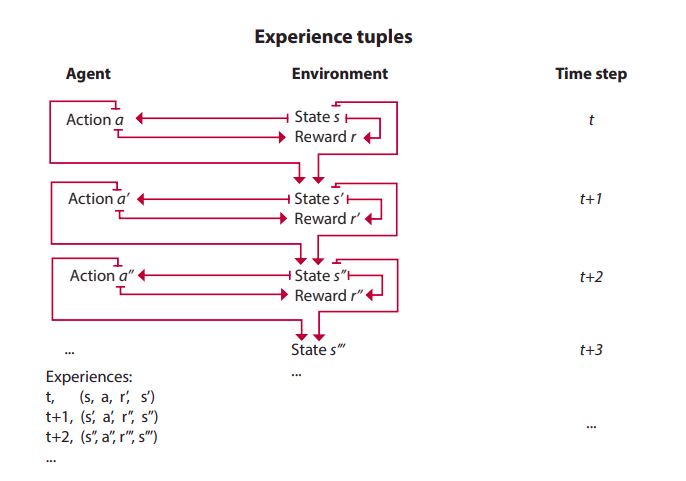
The task the agent is trying to solve may or mayn’t have a natural ending. Task which have natural ending, such as game, are called episodic tasks. Conversely, tasks that don’t are called continuing tasks, such as learning forward motion. The sequence of time steps from the begining to end of an episodic task is called an episode.
Sequential Feedback
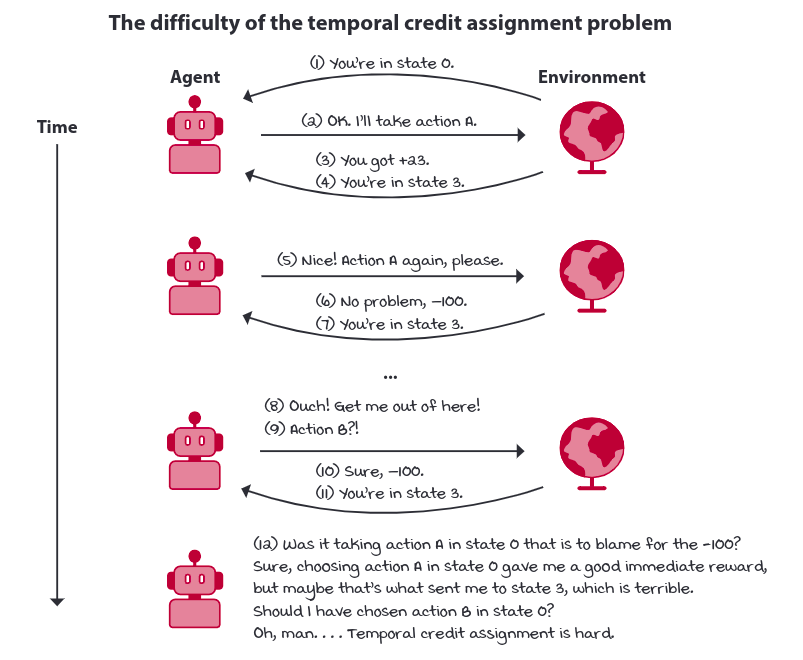
The actions taken by the agent may have delayed consequences. The reward maybe sparse and only manifest after several time steps. Thus the agent must be able learn from the sequential feedback which may give rise to a problem called temporal credit assignment problem. It is the challenge of determining which state and/or action is responsible for reward.
Evaluative Feedback
The reward recieved by agent may provide no supervision ie. reward may be weak. The reward mayn’t contain information about other potential rewards. Thus the agent must be able to learn from evaluative feedback which rises the need for exploration. The agent needs to be able to balance gathering of information and exploiting current information. This is referred to exploration versus exploitation trade-off.
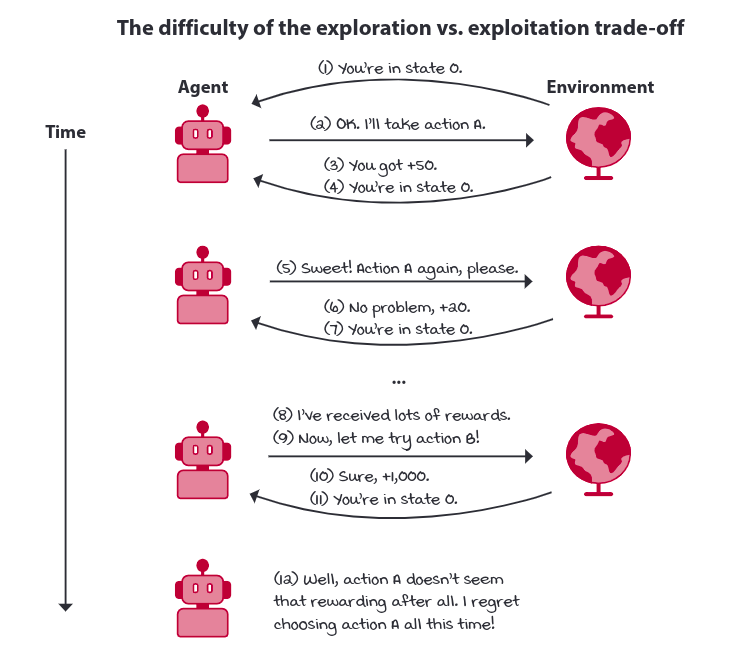
Sampled feedback
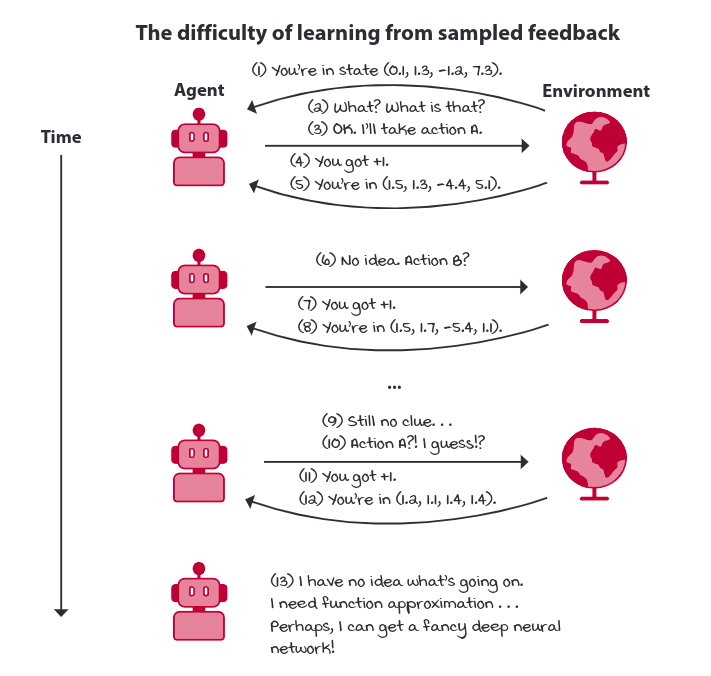
The reward received by agent is merely a sample and doesnt have access to the reward function. Also the state and action spaces are commonly large, even infinite, so trying to learn from sparse and weak feedback becomes a harder challenge with samples. Therefore, the agent must be able to learn from sampled feedback, and it must be able to generalize.
Agents that are designed to:
- Approximate policies: policy-based
- Approximate value function: value based
- Approximate models: model based
- Approximate both policies and value functions: action-crtitcs
Agents can be designed to approximate one or more of these components.
Deep reinforcement learning agents use powerful non-linear function approximation. The agent can approximate functions using a variety of ML methods and techniques.